2023年8月30日云从科技(688327)发布公告称公司于2023年8月25日召开业绩说明会,百川财富(北京)投资管理有限公司唐琪、东源启真(深圳)投资顾问企业(有限合伙)罗晨兮 秦翼恒、广东冠达菁华私募基金管理有限公司岳永明、国金证券股份有限公司纪超、国联证券股份有限公司黄楷、国盛证券有限责任公司陈泽青、海南象限基金管理有限公司杨宸、杭州锦成盛资产管理有限公司王懿晨、杭州致道投资有限公司刘福杰、华西证券股份有限公司赵宇阳、华夏财富创新投资管理有限公司刘春胜、北京城天九投资有限公司周晓玲、吉林长白山股权投资管理有限公司宁世恒、佳许盈海(上海)私募基金管理有限公司赵天武、江苏瑞华投资管理有限公司章礼英、巨柏资产管理(香港)有限公司王睦恺、君义振华(北京)管理咨询有限公司白璐、宁银理财有限责任公司毛子瑞、瑞银证券有限责任公司张维璇、上海丰仓股权投资基金管理有限公司路永光、上海杭贵投资管理有限公司饶欣莹、上海嘉世私募基金管理有限公司李其东、北京益安资本管理有限公司芦迪 尹加和 刘耀武、上海金辇投资管理有限公司景柄维、上海隽赐投资管理有限公司王一之 陈小艺、上海明河投资管理有限公司姜宇帆、上海摩旗投资管理有限公司沈梦杰、上海牛乎资产管理有限公司赵帅、上海浦东发展银行股份有限公司黄思慧、上海谦心投资管理有限公司柴志华、上海申银万国证券研究所有限公司洪依真、上海证券有限责任公司李想、深圳红方私募证券基金管理有限公司谢登科、北京紫薇私募基金管理有限公司王冰、深圳进门财经科技股份有限公司赖思欣 王腾 王倩琳、深圳前海岳瀚资产管理有限公司谢正洋、深圳市尚诚资产管理有限责任公司杜新正、天堂硅谷资产管理集团有限公司刘军洁、万和证券股份有限公司赵维卿、兴合基金管理有限公司侯吉冉、兴业证券股份有限公司陈鑫、誉辉资本管理(北京)有限责任公司郝彪、长城证券股份有限公司黄俊峰、浙商证券股份有限公司陶韫琦 刘雯蜀 王婷、财通证券股份有限公司董佳男 杨烨、郑州云杉投资管理有限公司李晟、中国建设银行股份有限公司胡璇 蔡浩荣、中华联合保险集团股份有限公司刘佑成、中泰证券股份有限公司王雪晴 闻学臣、中信建投证券股份有限公司甘洋科 丁然、中信证券股份有限公司胥洞菡 徐正源 丁奇、中邮人寿保险股份有限公司朱战宇、中邮证券有限责任公司丁子惠 王达婷、大家资产管理有限责任公司王箫、东方财富证券股份有限公司马行川、东方证券股份有限公司宋海亮、东兴基金管理有限公司张胡学参与。
具体内容如下:
问:公司从容大模型最新的版本更新到了 v5,后续模型的版本规划是怎样的?
答:后续模型版本的规划是以百亿模型为主体走行业落地方向,同时兼顾大模型性能的优异性和实用性的规划方向。一方面,是在跨模态、动模态的模型上面继续保持国内领先地位;另一方面,就是公司中央大模型主攻的逻辑是行业落地模型,所以会与行业头部的公司,比如神州信息等联合打造行业大模型。我们期望能在四季度把真正落地的产品做出来,这两个方面是公司主要的推进方向。
问:过去的大模型,更多的是 TO B端的,近期公司发布了一个 TO C端的集成大模型的 AI鼠标,后面在 TO C端又是怎么考虑的?
答:公司在商业模式上的主要思路是,人工智能单点技术在 C 端并不能直接产生性能优异的产品,但有了大模型的底座加持后,就可以推进 SMB端和 C端的产品。所以公司开始研究针对 SMB端和C端的模型矩阵和产品矩阵,比如刚才讲到的 I鼠标,它等于是一种硬件入口,让客户可以体验到自主安全、可控的 I 服务。后面我们会形成一系列实际场景应用的产品矩阵提供给客户,比如说对于 SMB端的客户而言,能够高效获客,降低成本是最重要的,所以我们帮他们把智慧营销、智能客服、数字直播等等直接联动起来。后续等公司产品陆续出来后,我们也会跟一些优秀的大渠道商,包括跟运营商、华为等公司形成合作关系,快速引入 SMB端客户。另外,C端的流量本身很重要,也能够帮助我们形成用户反馈数据的闭环,推动核心模型以及产品快速迭代,形成一个整体的系统。
问题 3:目前上市之前包括公司在内的几家头部 AI企业,收入端保持比较高的增长,但是在费用端怎么实现盈利?目前来看行业应用端和解决方案端还是面临比较大的压力,从现在这个节点来看,公司目前的关注点有没有侧重?如何去平衡盈利和投入之间的关系? 回 复:AI头部企业都存在收入端和费用端平衡点的问题,这其实跟 AI整个技术发展节奏有关系简单地说是在大模型出来之前,还在以解决方案为主体的盈利模式时,每个方案都需要投入大量的新的研发资源,同时还需要顶尖的人才,这导致了成本比较高,且限制了工业化推广能力,边际成本比较高,所以会出现收入增长,投入也在增长的现象。随着大模型出现以后,终于出现了契机,其实可以相当于一次性投入建设大模型,后续的推广成本会有明显的下降。在此情况下,公司的主要方向就是转向产品化和服务化。首先是实现行业场景的标准化产品。然后是服务化,一方面,是直接提供模型服务,另一方面除了简单的模型服务,还可以提供在应用场景内的大模型服务,比如建设直播数字人,能直接取代原来需要的人力,同时营销更有效率,给用户带来更好的体验。这样一来付费方式就从原来的项目性付费转化成持续经营性的付费模式。回到关于投入和盈利平衡点的问题,首先明确的是,在当前阶段是需要持续投入的因为大模型本身就是需要先投入后持续产生好的边际效应。其次,在下半年我们的盈利情况会比上半年和去年下半年有所好转,从今年四季度开始体现由大模型带来的营业结构改变的好处。最后,随着产品化和服务化能力的不断提升,大模型的边际效应也会逐渐显露出来,商业模式由 TO G端到 TO B、TO C和SMB端转变的优势也会逐渐凸显,会对未来持续经营能力和盈利能力产生很好的帮助。 问题 4:目前公司在 AI算力这一块有哪些布局?未来随着定增的顺利落地,算力这一块是怎样规划会有多大规模的扩充? 回 复:一方面,公司本身有一些算力储备,按今年大模型的规划也做了自己的采购和布局,现在算力相对充足。目前公司在重庆建了智算中心,接下来随着业务的进一步发展,后续通过与政府和运营商的合作联合布局云计算中心和测算中心,以更有优势的成本扩展专利池。这种合作不仅仅是限于自用的,更多的是联合运营和推广,比如现在的一些云计算中心和测算中心,如果只是提供服务器这方面的底层设备是没有优势的,所以需要跟头部的 AI公司进行绑定,让这个计算中心的智慧化起来,吸引更多的开发者和使用者。另一方面,我们也有行业头部客户,在推训一体方面会自己布局算力,一般客户不会大规模采购预训练部分的算力,但是到了推理侧,有些客户可能需要,我们也可以提供这部分的算力。 问题 5:公司订单情况是有比较好的改善,请拆解一下订单的改善大多数是来自政府端或者 G 端,还是说企业端这边的订单改善比较明显? 回 复:目前的订单落地方面还不完全是基于模型的,因为模型真正落地还需要一定的周期。 目前大概有 50%以上还是源于智慧治理,智慧出行方面大概占比 19%,智慧金融是在 13%,剩下的就是智慧商业、泛 AI等领域,我们后续会不断调整结构,包括在手订单和潜在商机方面都在从 G端向 B端及消费端去转变和调整。 问题 6:如何看待公司的大模型和一些比较优秀的开源大模型之间彼此竞争的关系? 回 复:开源的统一大模型反映了基础的水平提到了一定的高度,其优势在于大家可以通过互相学习借鉴,共同推动大模型的发展和完善。但是要落地到具体场景里面,还是需要有扎实积累,以及优秀人才 首先,实现场景落地就需要解决跨模态的问题,比如说要做一个智能运维的系统,所使用的模型就必须把视觉完全打通,必须得在现场通过视觉观测能够确定现有设备的情况,不管是在巡检的时候,还是在实际检修的时候,大模型要能自己看得懂说明书,还有能力将说明书上的草图跟现场非常复杂环境里设备的各个环节能一一对应起来,如果没有很强的视觉能力模型,就做不了这个工作。单单是跨模态的能力基本上就把大部分的公司拦在门外了。其次,真正行业场景落地的时候还需要把内容与行业数据相结合这一步也是目前简单的开源模型无法完成的。最后,是关于成本的问题,即便是在一些 Demo Case里面开源模型取得了比较好的效果,但是真正在客户侧落地的时候,更看重的是工程化的能力,既要好又要便宜又要快。在这种情况下,我们并不是简单丢个千亿模型在这放着,而是通过不断优化,使得整体模型轻量化,把推理成本降到足够低。 问题 7:这轮 AI技术革命有一种说法,未来的模型和算法可能会走向统一,公司在小模型时代的技术积累,到了大模型时代,这些积累哪些会受到冲击?哪些还能够发挥它的价值? 回 复:目前来看,至少 5年以内,模型是肯定不可能统一的。首先,最核心的原因是实际落地的时候,客户的要求是他的场景里面提供一个最优的选择,是不会接受用一个大的模型去做推理,然后把这种推理的成本加到客户的身上,所以这个模型就已经统一不了。其次,即使是 Open AI目前做 TO C的模型,仍然是分成几个模型,比如偏重于编程的模型和偏重于聊天的模型等等。偏重于聊天的,相当于我们人比较外向,偏重于编的程,相当于人比较内向和严肃,所以说模型会不会走向统一,在短期之内是个伪命题。很多年以后,如果技术有很大的变化那不好说,但是目前这一波里面是不可能出现。再次,对于公司这种长期研发核心技术的公司,技术积累其实是全方位的积累,不仅仅是少数算法上面的积累,而是整个模型强度的积累。比如人脸识别算法,因为人脸识别实际上是对可信度要求非常高,单个的模型所要求的强度是非常高的,不可能统一到某个模型中去。此外,还有人才的积累,从核心技术研究的人才,从数据处理,尤其是大规模数据处理、整个数据的架构、数据的初筛、数据的精筛、数据的标注到数据的整个算法框架,都是需要大量的人才积累。此外,还包括平台方向处理集群的计算,平台本身的架构以及工程化实践能力,对模型的吸收、处理和蒸馏等等这一类的人才积累。最后,还有把算法与行业原有的软件设备相结合的能力积累,如果说不是长期真正浸润在行业领域的公司,在这块能力上的差距还是挺大的目前国内真正做模型且效果好的公司都是在这方面有积累的公司,比如说像科大讯飞在语音识别模型效果好就是因为长期深耕在这一领域。 问题 8:我们之前有哪些积累的数据是比较高质量的,未来我们会采取一些什么样的措施去获取和积累更多这种高质量的训练数据? 回 复:公司本身有很多自己数据的积累,但最重要的是跟客户建立起使用场景和过程的数据闭环是一种活的数据,这一点公司的优势比较大。现在模型大众能力是可以根据通用数据锻炼出来,但是行业数据如何跟模型形成闭环互动是比较难的,需要跟行业专家一起形成反馈闭环的机制,从而挖掘出行业里逻辑,这样才能把场景应用模型训练出来,这并不是说通过在行业里摄像头采集数据能积累沉淀的。这也是我们要跟头部的客户进行战略合作或者建立联合实验室的原因,就是希望通过这种方式能够真正把这类数据积累起来,形成公司的价格壁垒。云从科技(688327)主营业务:从事人工智能算法研究及应用,面向客户提供人机协同操作系统和人工智能解决方案。
云从科技2023中报显示,公司主营收入1.64亿元,同比下降58.16%;归母净利润-3.04亿元,同比上升6.53%;扣非净利润-3.21亿元,同比上升8.93%;其中2023年第二季度,公司单季度主营收入1.18亿元,同比下降33.54%;单季度归母净利润-1.62亿元,同比上升22.72%;单季度扣非净利润-1.7亿元,同比上升24.4%;负债率45.56%,投资收益573.71万元,财务费用-79.07万元,毛利率57.76%。
该股最近90天内共有1家机构给出评级,增持评级1家;过去90天内机构目标均价为19.0。
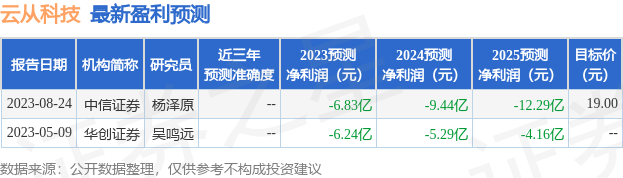
以下是详细的盈利预测信息:
融资融券数据显示该股近3个月融资净流入5256.32万,融资余额增加;融券净流入1.46亿,融券余额增加。
以上内容由根据公开信息整理,由算法生成,与本站立场无关。力求但不保证该信息(包括但不限于文字、视频、音频、数据及图表)全部或者部分内容的的准确性、完整性、有效性、及时性等,如存在问题请联系我们。本文为数据整理,不对您构成任何投资建议,投资有风险,请谨慎决策。