一个量化策略在交易环境中运行时,实时数据的处理通常是由事件驱动的。为确保研发和生产使用同一套代码,通常在研发阶段需将历史数据,严格按照事件发生的时间顺序进行回放,以此模拟交易环境。DolphinDB 提供了replay函数进行静态数据的回放,即将历史数据按照时间顺序以“实时数据”的方式注入流数据表中。对具有相同时间戳的数据,还可以指定额外排序列,使数据回放顺序更接近实时交易场景。
如何回放更高效?
回放的原理是从数据库中读取需要的行情数据,并根据时间列排序后写入到相应的流数据表。因此,读数据库并排序的性能对回放速度有很大的影响,合理的分区机制将有助于提高数据加载速度。
此外,在实际的投研过程中,往往会有多个用户同时通过 C++、Python 等客户端提交数据回放请求。对行情回放服务进行工程化管理将极大提高投研效率。为了响应量化投研中回放服务的工程化需求,我们基于 DolphinDB 分布式数据库、回放功能以及 DolphinDB API,搭建了一个基础的行情数据回放服务,给出了行情数据最佳分区存储方案,并提供了多用户多支股票多天多表交易所行情数据回放最佳实践方案。用户可以在此基础上快速搭建自己的行情回放系统。
性能展示:一天全速并发回放
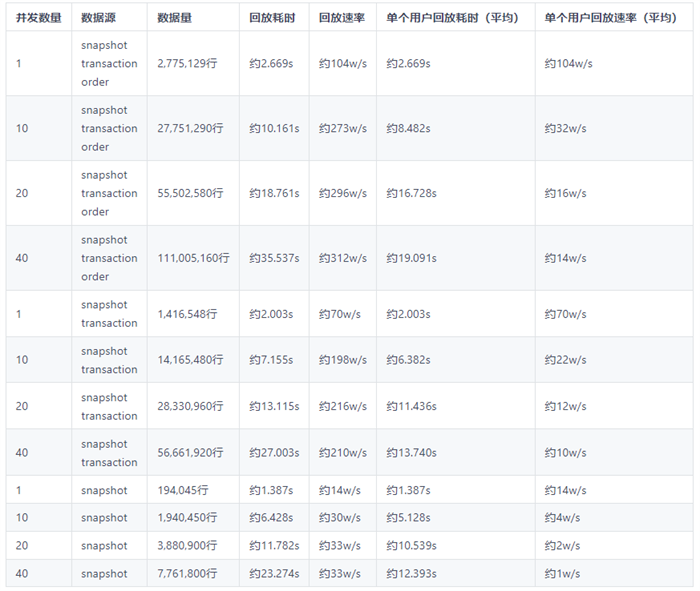
我们选取了深交所 2021 年 12 月 1 日 50 只交易股票数据,在 linux 后台同时启动多个 C++ API 提交回放的程序,提交多个并发回放任务,来测试这套架构的性能表现。
·回放耗时= 所有回放任务最晚结束时间 - 所有回放任务最早收到时间
·回放速率= 所有用户回放数据量总和 / 回放耗时
·平均单个用户回放耗时=(所有回放任务结束时间和 - 所有回放任务开始时间和)/ 并发数量
·平均单个用户回放速率= 单个用户回放数据量 / 平均单个用户回放耗时
性能展示:跨天全速回放
测试的交易日范围从 2021 年 12 月 1 日至 12 月 9 日共 7 个连续交易日,选取深交所 50 只交易股票数据,linux 后台启动 C++ API 提交回放的程序,提交多天回放任务。
·回放耗时= 回放任务结束时间 - 回放任务收到时间
·回放速率= 回放数据量 / 回放耗时

可以看到,这套行情数据回放方案在中高频数据下仍然具有强大性能,且调用方便、实现简单。下面为大家简单介绍一下架构与搭建步骤。完整的教程已发布在官方知乎,可以点击文末阅读原文查看。
基于 DolphinDB 的行情回放系统
我们搭建的行情回放服务基于 3 类国内 A 股行情:逐笔委托数据、逐笔成交数据和 Level 2 快照数据,支持以下功能与特性:
·C++、Python 客户端提交回放请求(指定回放股票列表 、回放日期、回放速率、回放数据源)
·多个用户同时回放
·多个数据源同时有序回放
·在时间有序的基础上支持排序列有序(如:针对逐笔数据中的交易所原始消息记录号排序)
·发布回放结束信号
·对回放结果订阅消费

行情回放服务架构
这套行情回放服务架构包含以下几个模块:
·行情数据接入:实时行情数据和历史行情数据可以通过 DolphinDB API 或插件存储到 DolphinDB 分布式时序数据库中。
·函数模块封装:数据查询和回放过程可以通过 DolphinDB 函数视图封装内置,仅暴露股票列表 、回放日期、回放速率、回放数据源等关键参数给行情服务用户。
·行情用户请求:需要进行行情回放的用户可以通过 DolphinDB 客户端软件(如 DolphinDB GUI 工具、DolphinDB VS Code 插件、DolphinDB API 等)调用封装好的回放函数对存储在数据库中的行情数据进行回放,同时,用户还可以在客户端对回放结果进行实时订阅消费。此外,支持多用户并发回放。
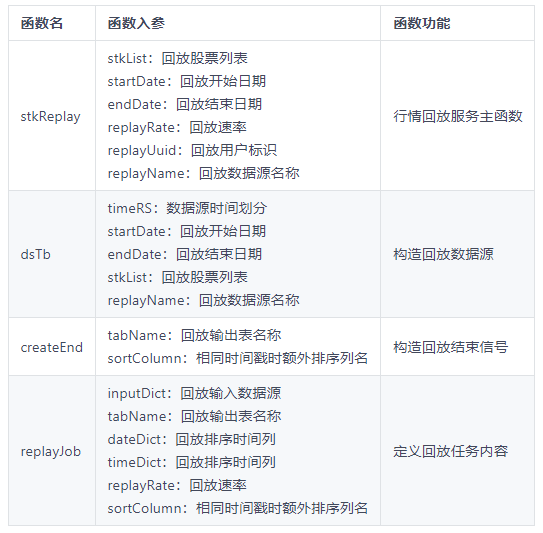
回放过程中的主要函数及功能如下表所示,所有函数都已封装成视图以便通过 API 等方式调用。
怎么快速搭建?

回放服务搭建步骤
Step 1:服务提供者设计合理分区的数据库表,在 DolphinDB 集成开发环境中执行对应的建库建表、数据导入等脚本,以将历史行情数据存储到 DolphinDB 分布式数据库中作为回放服务的数据源。
Step 2:服务提供者在 DolphinDB 集成开发环境中将回放过程中的操作封装成函数视图,通过封装使得行情服务用户不需要关心 DolphinDB 回放功能的细节,只需要指定简单的回放参数(股票、日期、回放速率、数据源)即可提交回放请求。
Step 3:服务提供者在外部程序中通过 DolphinDB API 调用上述函数视图实现提交回放的功能。在第四章将给出 API 端提交回放任务的 C++ 实现和 Python 实现。
我们给出了3 类行情数据的最佳分区存储方案及建库建表脚本、全部函数视图的定义脚本、提交回放以及 API 端订阅与消费的代码实现。大家可以关注DolphinDB公众号查看完整脚本与搭建教程。





